Displaying posts
tagged licensing
![]()
by on February 3, 2024
Across organizations who develop and deploy software, there are a wide range of time-sensitive concerns that arise. Perhaps the most diligent team that responds to such time-sensitive concerns is the cybersecurity team. It is crucial for them to quickly understand the security concern, patch it without introducing any regressions, and deploy it. In extreme cases this is all done within a few hours — a monumental task crammed into less time than a dinner party (and often replacing such a social event at the last minute; these teams are truly dedicated).
Many other teams exist across organizations for different levels of risk and concern. In our experience, on average among many companies, the team that receives among the lowest priorities is the team that responds to concerns about a company's copyleft compliance. Now we can think of some reasons for this: the team is often not connected to the team that collated the software containing copylefted code, or that latter team was not given proper instruction for how to comply with the licenses (and/or does not read the licenses themselves). So the team responding when someone notes a copyleft compliance deficiency is ill-equipped to handle it, and is often stonewalled by developer teams when they ask them for help, so the requests for correct source code under copyleft licenses usually languish.
With this in mind, we at SFC are helping prioritize the copyleft compliance concerns an organization may face due to some of the above. To reflect the importance of teams responding to copyleft compliance concerns, we recommend that companies create a team that we are calling a "Copyleft Compliance Incident Response Team" (CCIRT). This will help convey to management the importance of properly staffing the team, but also how it must be taken seriously by other teams that the CCIRT relies on to respond to incidents. Where companies employ Compliance Officers, they will likely be obvious leaders for this team.
Now some companies may not need a CCIRT. Unlike security vulnerabilities, failing to comply with copyleft licenses is entirely preventable. If you know your company already has policies and procedures that yield compliant results (of the same form as compliant source candidates that we praise in the comments on Use The Source), then there is no need for a CCIRT. However, our experience shows that most companies do not have such policies and procedures, in which case a CCIRT is necessary until such policies and procedures can reliably produce compliant source candidates from the start.
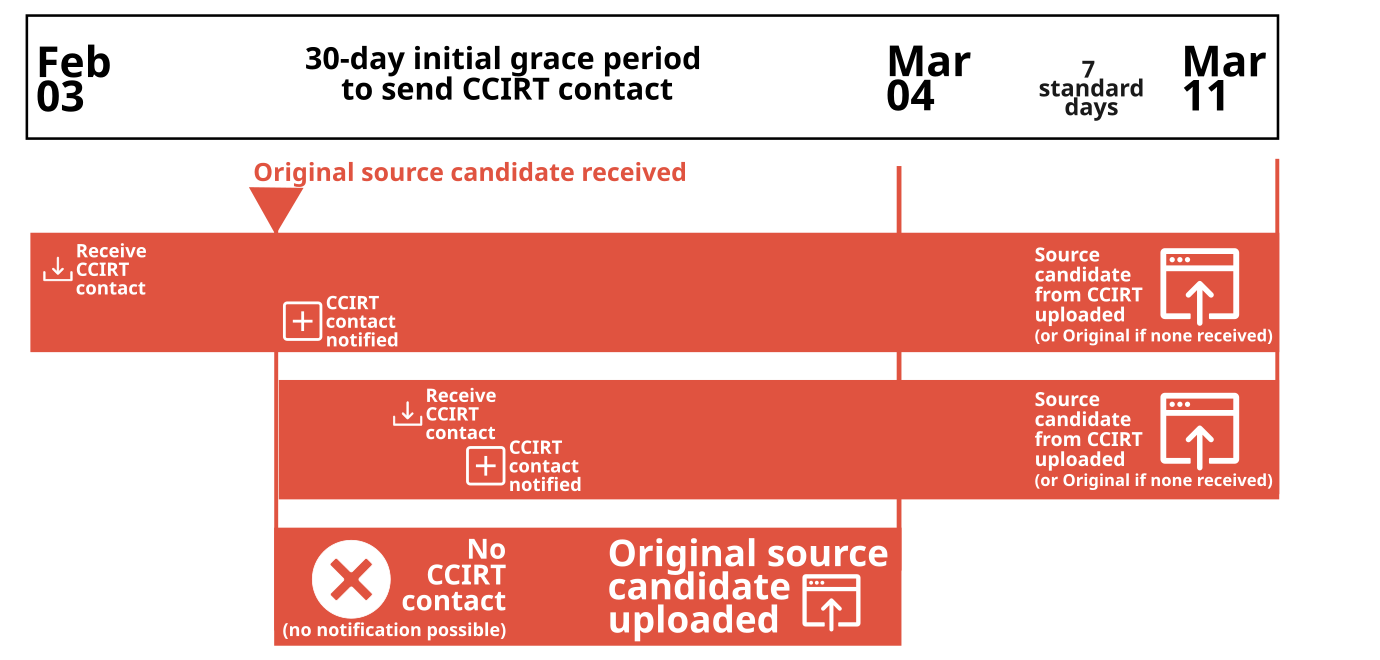
We recently launched Use The Source (alluded to above), which helps device owners and companies see whether source code candidates (the most important part of copyleft compliance) are giving users their software right to repair, i.e. whether they comply with the copyleft licenses they use. We realize companies may be concerned about SFC publishing their source candidates before they have had a chance to double-check them for compliance, due to some of the issues with policies and procedures mentioned above. As a result, we are giving companies the opportunity to be notified before we post a source candidate of theirs, so that they can take up to 7 days to update the candidate with any fixes they feel may be necessary before we post it. And the sooner a company contacts us, the better, as we are offering up to 37 days from the launch of Use The Source before we publish candidates we receive. See our CCIRT notification timeline for details. For historical purposes, the additional grace period that we provided at launch time is detailed here.
We hope that this new terminology will help organizations prioritize copyleft compliance appropriately, and that everyone can benefit from the shared discussions of source candidates and their compliance with copyleft licenses. We look forward to working with companies and device owners to promote exceptional examples of software right to repair (through our comments on Use The Source) as we find them.
by on October 12, 2023
In SFC's ongoing lawsuit against Vizio asking to receive the source code for the copylefted components on their TVs, last week we had a hearing with the judge to discuss the Motion for Summary Judgment that Vizio filed (requesting that the court reject our case before it even went to trial). A couple of our staff attended in-person (in an Orange County courthouse in Southern California) while others, like myself, watched remotely.
I was hoping to be able to use a standard interface to view the proceedings (such as streaming video provided to a <video/> element on a webpage), but unfortunately that was not available. The only way to view hearings in this court remotely is via Zoom, which SFC has talked about recently. This presented me with a conundrum - do I join via Zoom to see what was said? Or am I prevented from accessing this civic discourse because the court chooses not to use a standard video sharing method, preventing a large segment of society from taking part? As part of their normal practice, the court does not record (nor allow recording except through an official court reporter that can be hired by the parties to take a textual transcript) of proceedings, so I needed to decide with some urgency how to proceed, as failing to join now would mean I couldn't see the hearing at all, neither now nor in the future.
I am not sure how other countries approach this problem, and maybe it is no different elsewhere, but it did concern me deeply how this technical decision to demand the use of proprietary software could leave so many people disenfranchised, both with respect to their legal system, and other public services as well.
As part of SFC's policy to allow the use proprietary software if it is critical to our mission, I decided that it was more important for me to be able to view the proceedings (and avoid charging many hundreds of dollars to SFC for an international flight and hotel). Note that SFC would never require this of me, and would gladly pay for me to attend in-person to avoid the proprietary software, but I felt personally it was the right decision for me to make in this context.
Once this dilemma was resolved (for better or worse), I went through the technical steps required to join the Zoom call for the court hearing, where I was presented with this text:
By clicking "Join", you agree to our {0} and {1}.
Now there were no links to {0} or {1}, so I made some guesses as to what I was agreeing to. In the best case, I was agreeing to nothing, and in the worst case I was agreeing that 0 and 1 provided the foundation for all humanity which, while potentially troubling, did have a certain appeal as a technologist. In any case, I clicked Join (possibly leaving an indelible mark on the future of the universe) and was at last able to observe the hearing, after dialing in by (SIP) phone for the audio, to reduce the amount of proprietary code being run for me to view the hearing.
The hearing event itself was familiar to those who have attended such court proceedings - there were many other cases heard that day, that touched on issues such as whether you could get a DUI while riding a horse (answer: yes), to much more serious and unfortunate clear instances of DARVO tactics in domestic disputes (which we hope will not ultimately sway the judge). It appeared the judge wanted to save our hearing for last, possibly due to its complexity or novelty. The lawyers in most of the other matters appeared remotely.
Once the other cases were heard, the judge turned to us, with both our lawyers and Vizio's lawyer physically present in the courtroom. She asked Vizio to go first (since it was Vizio's motion), and their lawyer went over the points from their Motion for Summary Judgment, eventually clarifying seven specific objections Vizio had made to our case in its motion - the judge had clearly read our brief and wanted to know more on these seven topics given how we addressed them.
It was a bit jarring to hear my own name mentioned in court, as one of the objections was to an email I had sent to Vizio when we informed them they were violating the GPL. While not a problem for our case, it reminded me of the need to be extra careful, since anything we say to a company who violates the GPL can end up in court. But it also reminded me of why it is important we do this: if people feel scared to file lawsuits when companies fail to comply with the software freedom licenses they choose to use, then we at SFC must step up and use our resources and substantial experience to make sure the unfounded claims by companies of how they should be able to get away with violating are firmly rebuffed.
After Vizio's lawyer had finished, the judge turned to our lawyers for a response. Our lawyers presented an excellent litany of reasons why SFC's case is not preempted by copyright (for example, there is an extra element, provision of source code, that copyright remedies do not provide), and why we have rights as a third-party to the GPL contract between Vizio and the developers of the software that Vizio chose to use (as an example, the GPL itself clearly states, "You [Vizio] must make sure that they [third-party recipients such as SFC], too, receive or can get the source code").
Our lawyers finished with some examples of how contract law works, where if you agree to make some copies, but don't pay the money required in the contract, then that's a contract claim, not a copyright claim. In that case, a party has stiffed the beneficiary on the money. And in our case, as our lawyer so eloquently ended the hearing: "Vizio has stiffed us on the code".
We are extremely proud of our lawyers in this case, especially the two lawyers who argued in-person for us on Thursday: Naomi Jane Gray and Don Thompson, as well our General Counsel Rick Sanders. Whether companies are held accountable for following the software right to repair licenses they choose to use is immensely important - they need to give us the same rights they have, and we're incredibly happy that our legal team are so laser-focused on this.
We look forward to hearing the judge's decision on this motion when it comes out (in the meantime, you can read the hearing transcript if you like). Whatever the result, we will keep fighting for your software rights, everywhere software is used, using the legal mechanisms available (when required), to make sure everyone can control their technology.
by on July 27, 2023
When it comes to the law, people working on software freedom are often most concerned about copyright and contract law (and the licenses we use under both), since these appear to most directly affect software freedom. How people can use, study, modify, and redistribute the software is naturally of paramount importance and these laws heavily affect those rights. Generally FOSS projects don't consider their brand as much as the software and community being built, and so other fields of law, like trademark, get less consideration.
However, trademark law can have a significant impact on what people can do with a FOSS project, including whether they can enjoy these rights at all.
Practical software freedom (the right to use, study, modify, and redistribute software you've received) requires meeting several conditions. First, that program must be under a Free and Open Source (FOSS) license. Second, the entity(ies) distributing the program must abide by the terms of the license. And third, there must be no additional restrictions that would inhibit your ability to exercise your rights under the license. (Copyleft licenses include extra verbiage to assure the third condition is met.)
For non-copylefted works, which do not have additional terms in the FOSS license to avoid additional restrictions, we have to verify that no external conditions effectively revoke the rights of users surreptitiously. While that situation is rare, the repercussions can be quite severe. Historically, for some famous software, we've faced such significant challenges. This post is advice to avoid repeating these mistakes of the past. Often, these mistakes occur due to aggressive trademark policies.
Trademarks have value for FOSS; they do reduce confusion between similar products, tools, or programs. When used appropriately, they ensure people know what program they're using, who is behind it, and what they can expect from its behavior. When stretched too far, trademark policies create huge problems in software freedom communities. Sometimes, aggressive trademark policies cause programs that would otherwise give users software freedom to no longer provide the rights users rely on to copy, share, and redistribute the software.
We explore below three historical examples — each of which provide different lessons on how appropriate trademark policies can respect software freedom. We end with a recent situation that could still go either way.
Let's start with Java. As early as 1996, Sun Microsystems was aggressively going after anyone who used the 4 letters "Java" in their name, even if there was no likely confusion. Occasionally, Sun had to apologize for this behavior. Contemporaneous commentators noted: "that doesn't mean that Sun intends to rein in its trademark hawks". As a result, software freedom activists wishing to implement a Java compiler were extremely careful to never use "Java" in a way that could cause Sun to object. One example is the first FOSS implementation of the Java standard library, which developers named "Classpath" (at the suggestion of SFC's now Policy Fellow, Bradley Kuhn) to avoid any whiff of "Java". While Sun later became more friendly to software freedom, this software-freedom-hostile trademark policy persisted for over a decade, creating significant extra work for anyone wanting to create or modify Java programs, as they navigated the confusing naming landscape of not-Java names used for Java tooling.
Next, consider PHP. Starting in 2000, the PHP authors decided to remove the option to use PHP under the General Public License, beginning with PHP version 4. This left users with only the PHP License as an option, which is non-copyleft, but includes extra restrictions beyond most non-copyleft FOSS licenses. Those restrictions specifically related to use of the PHP name. This policy led to substantial debate within many communities, including Debian. Debian eventually decided to create a special policy for PHP in order to feel comfortable redistributing and modifying PHP, which is memorialized on the FTP Masters' web site. Imagine the time and effort wasted by redistributors like Debian, who had to consider special cases for a specific software program. Ultimately, such licensing makes extra work for distributions like Debian, and creates uncertainty for people wishing to modify PHP — as they navigate a license used nowhere else that awkwardly pulls in a trademark policy as part of it.
Finally, and perhaps most importantly, consider the historical situation with Mozilla. Unlike the other two examples (with very little communication between trademark holders and distributors of the software), Mozilla did try to coordinate with groups like Debian. However, Mozilla's demands (beginning in 2004) could not be accommodated without major changes to the programs that Debian and other distributions provided to users. Mozilla was unable to successfully address the legitimate concerns the Debian community raised regarding its policies for a long period of time. As a result, Debian and others spent years doing extra work to rename Firefox, Thunderbird, and other Mozilla projects before distributing them to users. This is perhaps the worst outcome of an improperly-applied trademark policy, as it causes both substantial extra work, and also a loss of brand recognition. Users of Debian and other distributions needed to do extra research to find that they were in fact using Mozilla software that is very similar to the Mozilla-branded versions. Mozilla's retrograde policies for years hurt both the Debian and Mozilla communities. Eventually, Mozilla listened to the community, negotiated fairly, and the policy was changed. The result was a clarification on how reasonable changes to Mozilla programs could retain the Mozilla names, as discussed by the Debian Project Leader involved in the discussions and others in the renaming ticket. In line with core principle 8 of the Debian Free Software Guidelines, there was nothing Debian-specific about the clarification, so all distributors of Mozilla programs could benefit.
With all these examples of trademark policies gone wrong in the first couple decades of the software freedom movement, we must create better policies going forward. Open dialog between trademark holders and software distributors can alleviate concerns over trademark policies' reach, or at least allow distributors to quickly arrive at a conclusion on appropriate next steps. So we do encourage groups with trademark policies (especially those likely to change in the near future) to proactively reach out to those affected, and ask for discussion and/or input to ensure the software freedom community remains strong and healthy.
With this in mind, we turn our attention to Rust, a programming language whose main compiler implementation is managed by the Rust Foundation, a 501(c)(6) trade assocation, comprised of companies with a common business interest. While the trademark policy that is currently in place at the time of this writing appears to be largely accepted by the community, allowing Debian to distribute the Rust Foundation compiler (rustc) to its users per standard Debian policy, there is concern that a draft trademark policy currently under consideration may change this. The draft is available at this link (HTML-only version) — in accordance with SFC's organizational decision to run non-free JavaScript when it is crucial to our work (as this link requires), we have read the document at that link to confirm its contents.
The Rust Foundation's draft trademark policy may require substantial work to avoid the problems of the past. We hope that the Rust Foundation considers the history of trademarks and software freedom that we've discussed above. While the Rust Foundation did briefly open a comment form for public feedback on the above draft, it is unfortunately closed now. We are not aware of any outreach so far by the Rust Foundation to talk with key redistributors, such as Debian, to verify the changes would fit reasonably with long-standing FOSS redistribution policies. Accordingly, we hope the Rust Foundation will open another round of comments in order to solicit further feedback on their draft trademark policy.
After reaching out to someone who is involved with the Rust community and the Foundation, we understand that this policy is still a work in progress and look forward to hearing more about it in the weeks to come. The published policy is not in effect, and we encourage the Rust Foundation, in response to this article, to reach out to relevant parties and ask for assistance and feedback. We're of course happy to help however we can.
To keep our software freedom communities vibrant, communication is key. While we are excited to see the Rust Foundation open to public comment, we hope they will work with the larger FOSS community to find a trademark policy that benefits everyone. With decades of history and experience resolving these issues, the software freedom movement has what it takes to solve these and other pressing issues of today.
by on July 11, 2022
Suppose you go to your weekly MyTown market. The market runs Saturday and Sunday, and vendors set up booths to sell locally made products and locally grown and produced food. On Saturday, you buy some delicious almond milk from a local vendor — called Al's Awesome Almond Milk. You realize that Al's Awesome would make an excellent frozen dessert, so you make your new frozen dessert, which you name Betty's Best Almond Frozen Dessert. You get a booth for Sunday for yourself, and you sell some, but not as much as you'd like.
The next week, you realize you might sell more if you call it Al's Awesome Almond Frozen Dessert instead of your own name. Folks at the market know Al, but not you. So you change the name. Is this a morally and legally acceptable thing to do?
This is a question primarily regarding trademarks. We spend a lot of time in the Free and Open Source Software (FOSS) community talking about copyrights and patents, but another common area of legal issues that face FOSS projects (in addition to copyright and patent) is trademark.
In fact, FOSS projects probably don't spend enough time thinking about their trademark. Nearly ten years ago, Pam Chestek — a lawyer and expert in trademark law as it relates to FOSS and board member of OSI — gave an excellent talk at FOSDEM (2013), wherein she explored how FOSS projects can use trademarks better and to ensure rights of consumers — particularly when dealing with bad actors. Our own Executive Director, Karen Sandler, had also spoken about this issue as well. These older talks, in turn, spawned an ongoing conversation that continues to this day in FOSS policy circles.
Specifically, last week, we learned that the Microsoft Store was changing their policies, ostensibly to deal with folks (probably some of whom are unscrupulous) rebuilding binaries for well-known FOSS projects and uploading them to the Microsoft Store. Yet, this is a longstanding issue in FOSS policy. FOSS experts in this area would have been happy to share what's been learned over the last ten years of studying this issue.
The problem Microsoft faces here is the same problem that the MyTown market folks face if you show up trying to sell Al's Awesome Almond Frozen Dessert. The store/market can set rules that you will no longer be able to sell if you are found to infringe the trademark of another seller. The market could simply require the trademark holder to take trademark action themselves, or it could offer some form of assistance, arbitration, or other-extra-legal resolution mechanism0.
There is often temptation in FOSS to give special status to maintainers, or the original developer, or the copyright holder, or some other entity that is considered “official”. In FOSS, though, the only mechanism of officialness is the trademark — the name of the upstream project (or the fork). The entire point of FOSS is that for the code itself, everyone should have equal rights to the original developers, to the maintainers, or to any other entity.
We have faced this with our member project, Inkscape. While the Inkscape Project Leadership Committee has chosen not to charge for the version of Inkscape that they upload on Microsoft Store, we did see this very problem for many years before these app stores even existed. Namely, it was common for third-parties to sell Windows binaries on CD's for Inkscape in an effort to make a quick buck. We did trademark enforcement in these cases — not forbidding these vendors from selling — but simply requiring the vendors to clearly say that the product was a modified version of Inkscape. Or, if it was unmodified redistribution of Inkscape's own binaries, we required the vendor to note that the Inkscape project's website was the official source for these binaries.
I have often written to complain about copyright and patent law. I have my complaints about trademark law (and I've seen trademark grossly abused, even), but trademark laws tenets are really reasonable and solid: to ensure consumers know the source and quality of the products they receive.
The problem of concern here is one well handled by trademark. It doesn't need excessive app store rules; we don't need FOSS licenses to be usurped or superseded by Draconian policy. And, this solution to this particular problem has been long-known by FOSS. Pam's talk in 2013 explained it quite well!
The MyTown Market doesn't need to create a policy that forbids you from buying Al's Awesome Almond Milk on Saturday and reselling a product based on it on Sunday. They just need to let Al know his rights under trademark, and maybe offer a lightweight provisional suspension of your booth if the trademark complaint seems primia facie valid. But, most importantly, before it announces new rules with a 30 day clock, MyTown's leadership really should discuss it with the citizens first to find a policy that takes into account concerns of the people. Even if they fail to do that, there are MyTown's elected officials whose actions are accountable to the people. App store companies are accountable only to their shareholders, not the authors of the apps. Companies could benefit by learning that the FOSS community prioritizes respecting authors, protecting consumers' and users' rights, and by understanding that the line between user and contributor should blur. The FOSS marketplace functions because the community works.
0 I hesitate to even suggest that an app store should create an extra-legal process regarding trademark enforcement beyond the typical governmental mechanisms — lest they decide they have to do it. A major problem with app stores is that they create rules for software distribution that are capricious, and arbitrary. We all do want FOSS available on Microsoft, Apple, and Google-based platforms — and as such are forced to negotiate (or, rather, try to negotiate) for FOSS-friendly terms. Ultimately, though, the story of major vendor-controlled app stores is always the story of “just barely” being able to put FOSS on them, because the goal of these entities is to profit themselves, not serve the community. We prefer app stores like F-Droid that are community-organized and are not run for-profit.
{kind=link}